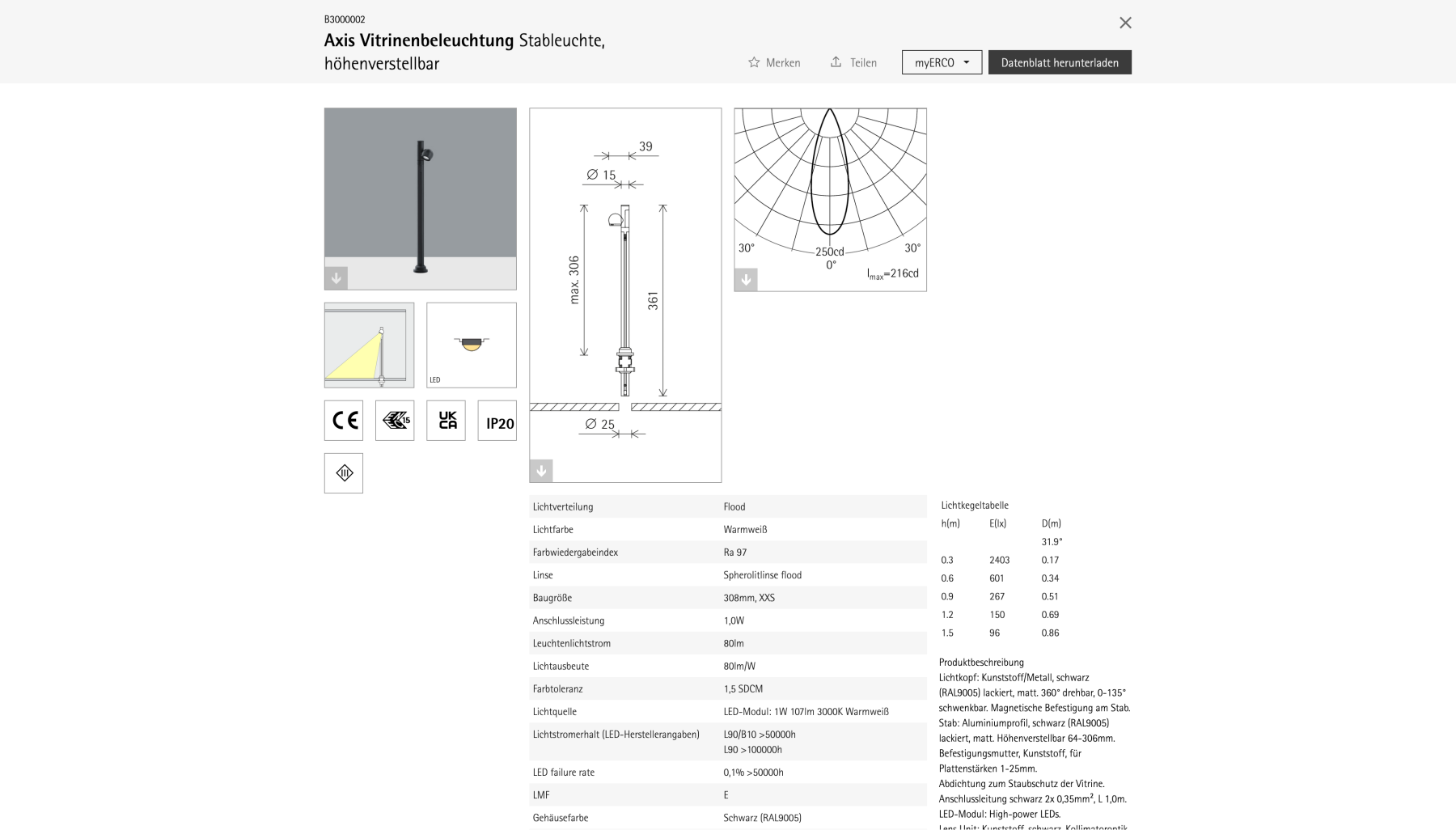
Die technische Grundlage bildet ein datenbankgestützter Prozess, bei der Produktspezifikationen über eine Anfrage als strukturierte Daten bereitgestellt werden. Diese Daten werden im Frontend verarbeitet und in eine visuelle Darstellung überführt. Die bisherige Abhängigkeit von vorgerenderten HTML-Dateien entfällt vollständig. Stattdessen wird die gesamte Darstellung zur Laufzeit erzeugt. Dies ermöglicht eine klare Trennung zwischen Datenhaltung, Logik und Präsentation.
Ein wichtiger Teil der Umsetzung ist, dass die entwickelten Funktionen mehrfach genutzt werden können. Die Bestandteile zur Anzeige und Verarbeitung der Spezifikationen wurden dafür in ein eigenes Modul ausgelagert. Dieses lässt sich unabhängig von der jeweiligen Anwendung verwenden und weiterentwickeln.
Besonders die Umsetzung der PDF-Generierung profitiert von den nun verfügbaren vollständigen strukturierten Produktdaten. Die Erzeugung von PDF-Datenblättern basiert auf einer eigenständigen Library, die direkt auf den strukturierten Artikeldaten arbeitet und sowohl im Client als auch im Backend ausgeführt wird. Je nach Anwendungsfall greift das System auf dieselbe Logik zurück, nutzt jedoch unterschiedliche Ausführungsorte. Wird beispielsweise ein einzelnes PDF durch Nutzer:innen erzeugt, erfolgt die Generierung direkt im Client. Sollen hingegen mehrere Dokumente gleichzeitig erstellt werden, übernimmt ein Backend-Service diesen Prozess, generiert die PDFs serverseitig und stellt sie gebündelt als Download in Form eines ZIP-Archivs bereit.
Der große Vorteil ist, dass in beiden Fällen dieselbe Logik und dasselbe zentrale Modul genutzt werden. Es sind keine zusätzlichen Umwege über den Browser erforderlich. Dadurch wird die Umsetzung einfacher, läuft schneller und ist weniger anfällig für Fehler.